The Helmholtz Method: Using Perceptual Compression to Reduce Machine Learning Complexity
Created by Gerald Friedland, Jingkang Wang, Ruoxi Jia, Bo Li and Dawn Song.
Introduction
This work is based on our arXiv tech report. We propose a fundamental answer to a frequently asked question in multimedia computing and machine learning: Do artifacts from perceptual compression contribute to error in the machine learning process and if so, how much?
Just like electricity doesn’t originate from the power outlet, pixels don’t randomly appear in an image file. Cameras are physical sensors that follow the laws of thermodynamics. Knowing this makes it easier to understand the properties of pixels as we train machine learners to recognize patterns in images.
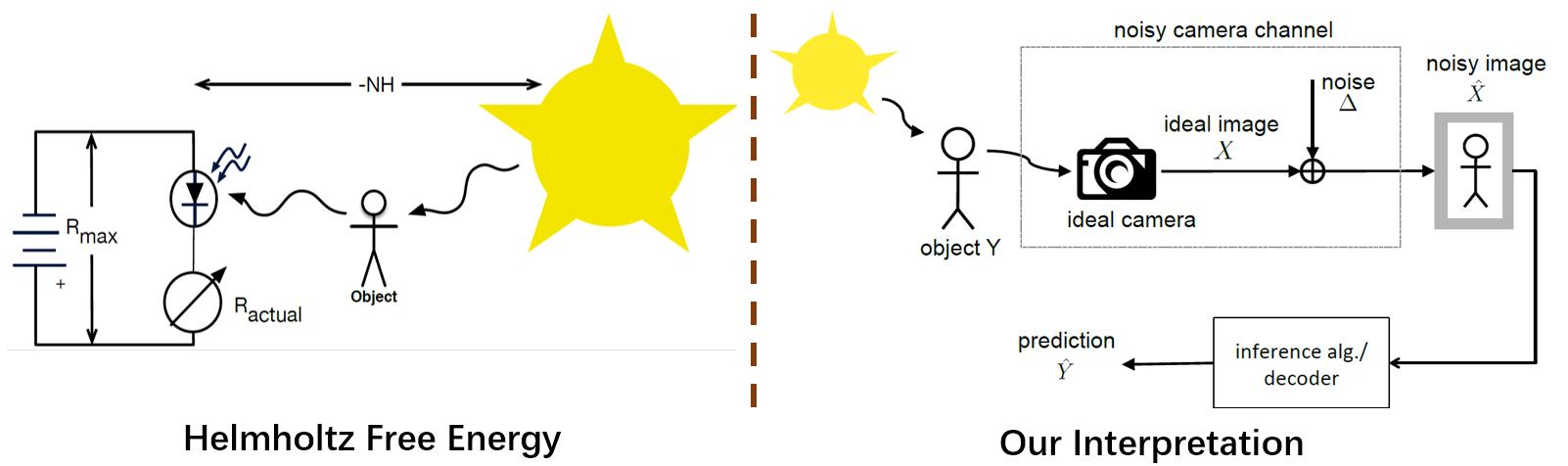
Our approach to the problem is a reinterpretation of the Helmholtz Free Energy formula from physics to explain the relationship between content and noise when using sensors (such as cameras or microphones) to capture multimedia data. The reinterpretation allows a bit-measurement of the noise contained in images, audio, and video by combining a classifier with perceptual compression, such as JPEG or MP3.
Extensive experiments show that, at the right quality level, perceptual compression is actually not harmful but contributes to a significant reduction of complexity of the machine learning process. Our work provides insights into the reasons for the success of deep learning.
In this repository, we release code and data for conducting perceptual compression while maintaining, or sometimes even improving, overall performance. Additionally, compressed models usually result in faster training convergent.
Requirements
- Tensorflow 1.4.0
- Keras 2.1.5
- Python 2.7
- CUDA 8.0+ (For GPU)
- Python Libraries: numpy pandas, h5py, pillow, imageio, librosa and librosa
- lame tool (for MP3 compression)
The code has been tested with Python 2.7, Tensorflow 1.4.0, CUDA 8.0 and cuDNN 5.1 on Ubuntu 14.04. But it may work on more machines (directly or through mini-modification), pull-requests or test report are well welcomed.
Usage
Data Preparation
We have evaluated our idea on images (CIFAR-10) and audios (IDMT-SMT-Audio-Effects).
To download and prepare CIFAR-10 data:
cd cifar/data
python convert_cifar10.py && python restore_images.py
sh prepare.sh
First, the data will be download from official website and decompressed automatically. Then images will be compressed using algorithoms and vaired image-quality (from 1 to 100) images will be put into quality_* directories. Finally, prepared hdf5 files train.h5 and test.h5 will also be generated in the directory, which are feed into neural networks in the training process.
To download the IDMT-SMT-Audio-Effects data, you could follow this repo.
Note to place twelve classes of audios (WAV) into audio/data/Samples folder.
Then use the script to prepare the data:
cd audio/data
python quantize.py
sh prepare-all.sh
Model Training
To train a model to classify images in CIFAR-10 (quality 5, architecure A)
cd cifar
python train.py --quality 5 --setting 0
Log files and network parameters will be saved to logs folder in default.
To see HELP for the training script:
cd cifar && python train.py -h (CIFAR-10)
cd audio && python train.py -h (Audio)
If enough GPUs are available, you could use scripts to train models with different settings (architecture, compression ratio). Remember to manually specify proper GPUs in the script (Each process occupies around 3500M graphic memory).
cd cifar
sh scripts/train-all-cnns.sh
Architecures
To evaluate our idea, we have designed six different architectures on CIFAR-10 and Audio dataset, respectively. The details of models (architectures, number of parameters) could be obtained from cifar_paras and audio_paras.
Citation
If you find our work useful in your research, please consider citing:
@article{helmholtz18,
title={The Helmholtz Method: Using Perceptual Compression to Reduce Machine Learning Complexity},
author={Gerald Friedland and Jingkang Wang and Ruoxi Jia and Bo Li and Dawn Song},
journal={arXiv preprint arXiv:1804.xxxxx},
year={2018}
}
Acknowledgements
This code is based on the previous works (All-Conv-Keras,panotti). Many thanks to the authors.
License
Our code is released under Apache License 2.0.